
Sitemap
A list of all the posts and pages found on the site. For you robots out there, there is an XML version available for digesting as well.
Pages
Posts
Future Blog Post
Published:
This post will show up by default. To disable scheduling of future posts, edit config.yml and set future: false.
Blog Post number 4
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 3
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 2
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
Blog Post number 1
Published:
This is a sample blog post. Lorem ipsum I can’t remember the rest of lorem ipsum and don’t have an internet connection right now. Testing testing testing this blog post. Blog posts are cool.
portfolio
Post Moore’s Law: Specialized Hardware Design for Scientific Computing
As Moore’s Law continues to plateau, traditional performance scaling based on transistor density has become insufficient for many scientific computing workloads, which are increasingly constrained by data movement, memory bandwidth, and latency rather than raw arithmetic throughput. In response, the computing ecosystem has shifted toward specialized hardware acceleration, where domain-specific architectures are co-designed with algorithms to overcome the memory wall and latency wall that limit conventional CPU- and GPU-based systems. This approach has demonstrated significant benefits across scientific computing domains, including linear algebra, signal processing, and simulation-driven workloads, by exploiting fine-grained parallelism, customized dataflows, and application-aware memory hierarchies. In the post–Moore’s Law era, specialized hardware acceleration is therefore a fundamental enabler for sustained performance and energy efficiency, allowing scientific applications to scale beyond the limits of general-purpose architectures through tight algorithm–hardware co-design.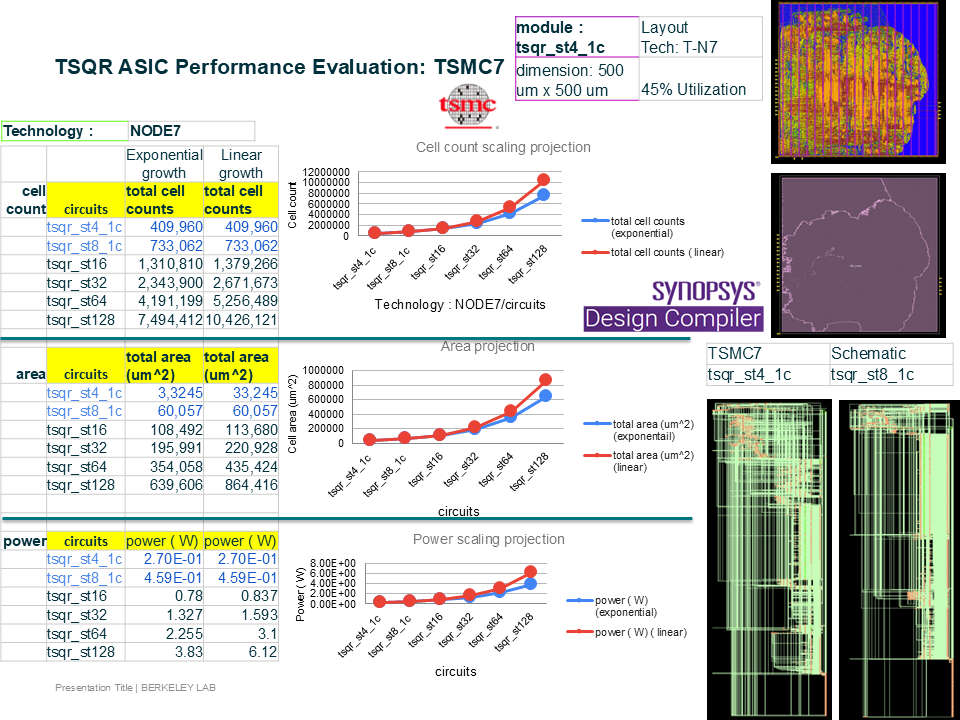
A Quantum-Classical Co-Design Framework for Scalable Quantum Circuit Simulation and Acceleration
As Moore’s Law continues to plateau, the industry has increasingly turned to specialized hardware design solutions to sustain performance scaling, particularly for artificial intelligence and high-performance computing applications. Representative examples of this paradigm shift include Google’s Tensor Processing Units (TPUs); Amazon AWS’s Graviton, Trainium, and Inferentia processors; Apple’s A- and M-series system-on-chips (SoCs); Meta’s Training and Inference Accelerator (MTIA); Microsoft’s Maia and Cobalt chips; Tesla’s Dojo accelerators; Broadcom’s custom AI application-specific integrated circuits (ASICs); and large-scale FPGA-based systems. Building on this trend, this project introduces a transformative quantum–classical co-design framework that tightly integrates circuit-cutting techniques with specialized multi-FPGA architectures to enable scalable and accelerated simulation. 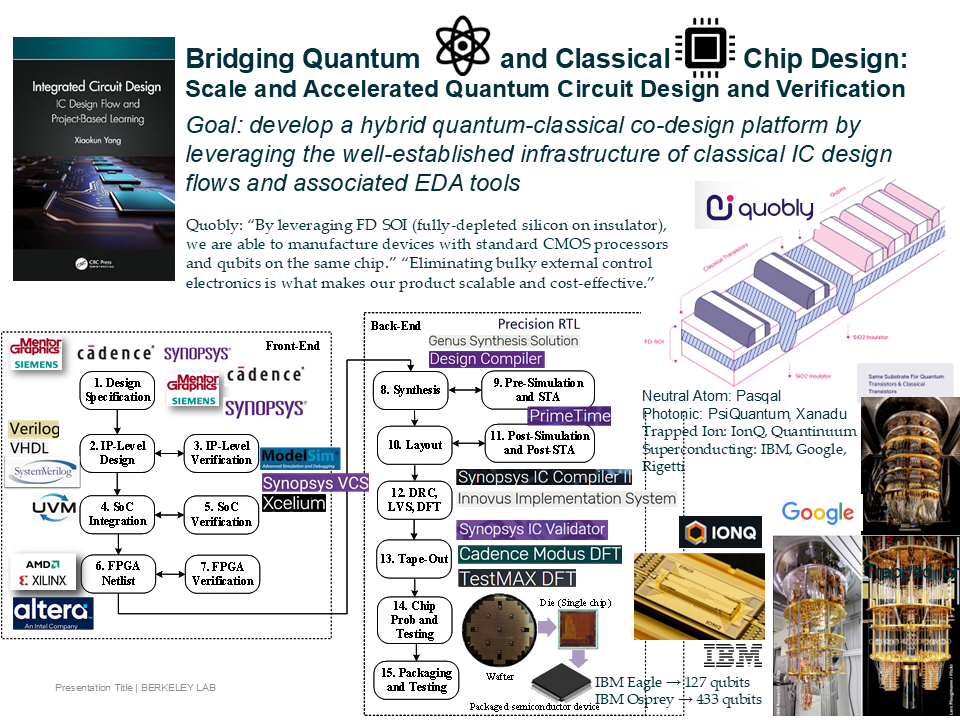
publications
Paper Title Number 1
Published in Journal 1, 2009
This paper is about the number 1. The number 2 is left for future work.
Recommended citation: Your Name, You. (2009). "Paper Title Number 1." Journal 1. 1(1).
Download Paper | Download Slides | Download Bibtex
Paper Title Number 2
Published in Journal 1, 2010
This paper is about the number 2. The number 3 is left for future work.
Recommended citation: Your Name, You. (2010). "Paper Title Number 2." Journal 1. 1(2).
Download Paper | Download Slides
Paper Title Number 3
Published in Journal 1, 2015
This paper is about the number 3. The number 4 is left for future work.
Recommended citation: Your Name, You. (2015). "Paper Title Number 3." Journal 1. 1(3).
Download Paper | Download Slides
Paper Title Number 4
Published in GitHub Journal of Bugs, 2024
This paper is about fixing template issue #693.
Recommended citation: Your Name, You. (2024). "Paper Title Number 3." GitHub Journal of Bugs. 1(3).
Download Paper
Paper Title Number 5, with math \(E=mc^2\)
Published in GitHub Journal of Bugs, 2024
This paper is about a famous math equation, \(E=mc^2\)
Recommended citation: Your Name, You. (2024). "Paper Title Number 3." GitHub Journal of Bugs. 1(3).
Download Paper
talks
Talk 1 on Relevant Topic in Your Field
Published:
This is a description of your talk, which is a markdown file that can be all markdown-ified like any other post. Yay markdown!
Conference Proceeding talk 3 on Relevant Topic in Your Field
Published:
This is a description of your conference proceedings talk, note the different field in type. You can put anything in this field.
teaching
Teaching experience 1
Undergraduate course, University 1, Department, 2014
This is a description of a teaching experience. You can use markdown like any other post.
Teaching experience 2
Workshop, University 1, Department, 2015
This is a description of a teaching experience. You can use markdown like any other post.