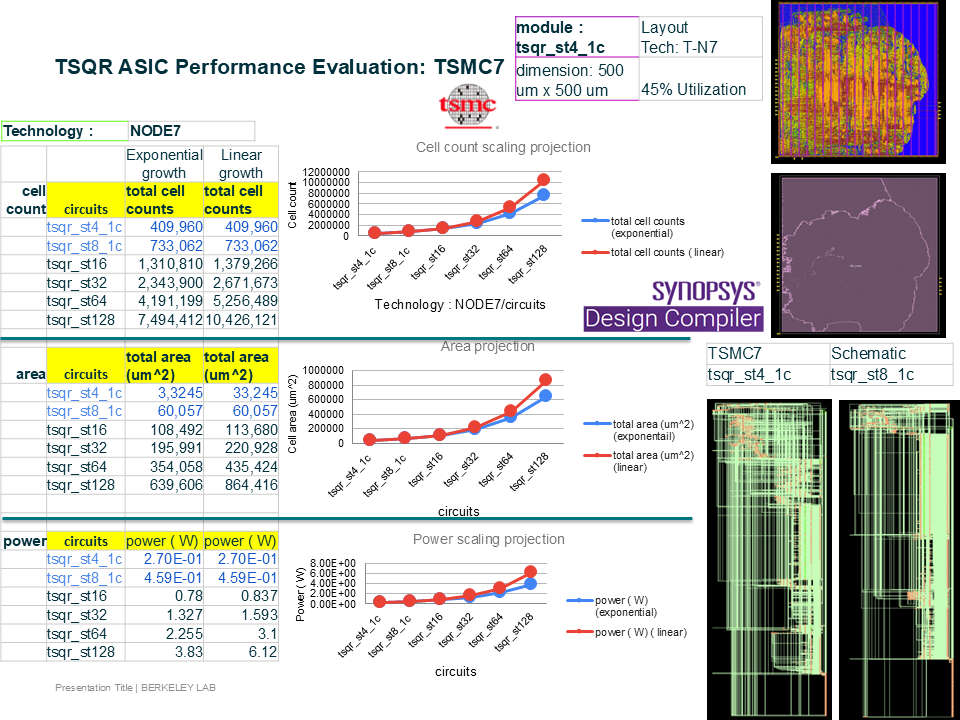
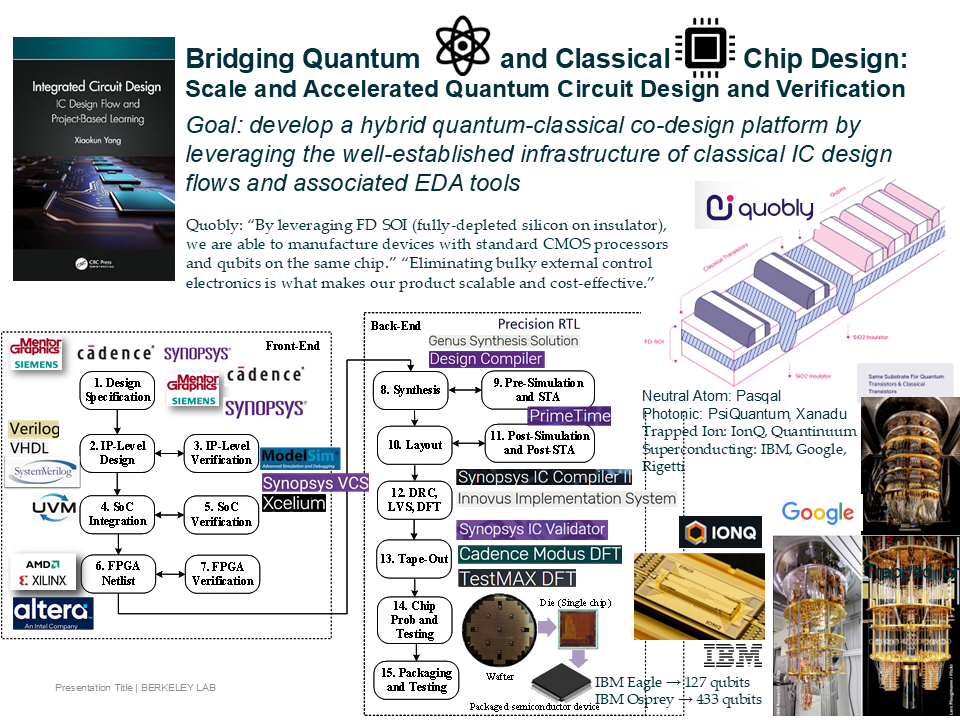
Post Moore’s Law: Specialized Hardware Design for Scientific Computing
As Moore’s Law continues to plateau, traditional performance scaling based on transistor density has become insufficient for many scientific computing workloads, which are increasingly constrained by data movement, memory bandwidth, and latency rather than raw arithmetic throughput. In response, the computing ecosystem has shifted toward specialized hardware acceleration, where domain-specific architectures are co-designed with algorithms to overcome the memory wall and latency wall that limit conventional CPU- and GPU-based systems. This approach has demonstrated significant benefits across scientific computing domains, including linear algebra, signal processing, and simulation-driven workloads, by exploiting fine-grained parallelism, customized dataflows, and application-aware memory hierarchies. In the post–Moore’s Law era, specialized hardware acceleration is therefore a fundamental enabler for sustained performance and energy efficiency, allowing scientific applications to scale beyond the limits of general-purpose architectures through tight algorithm–hardware co-design.